Programa de Doctorado Interuniversitario en Estudios Ingleses Avanzados: Lingüística, Literatura y Cultura (IDAES) – IDAES Graduate Day
References
Cohen, L., Manion, L., & Morrison, K. (2018). Research methods in education. Routledge.
Dornyei, Z. (2007). Research Methods in Applied Linguistics. OUP.
Hunston, S. (2019). Patterns, constructions, and applied linguistics. International Journal of Corpus Linguistics, 24(3), 324-353.
Loewen, S., & Plonsky, L. (2015). An A–Z of applied linguistics research methods. Macmillan.
Lukenchuk, A. (Ed.) (2013). Paradigms of research for the 21st century: Perspectives and examples from practice. New York, NY: Peter Lang Publishing.
McEnery, T., Brezina, V., Gablasova, D., & Banerjee, J. (2019). Corpus linguistics, learner corpora, and SLA: Employing technology to analyze language use. Annual Review of Applied Linguistics, 39, 74-92.
Mitchell, R., Myles, F. & Marsden, E. (2013). Second Language Learning Theories. 3rd ed. New York/London: Routledge.
Rose, H. & McKinley, J. (2017). The realities of doing research in applied linguistics. In McKinley, J & Rose, H. (eds.) Doing Research in Applied Linguistics. Routledge.
Stefanowitsch, A. (2020). Corpus linguistics. Language Science Press. Online edition.
Tyler, A. E., Ortega, L., Uno, M., & Park, H. I. (Eds.). (2018). Usage-inspired L2 instruction: Researched pedagogy (Vol. 49). John Benjamins.
It´s 11 years now that Johansson´s (2009:41) claimed that more systematic studies are needed in order to test the benefits of DDL and to discuss ‘students’ problems with corpus investigation’. The meta-analyses carried out by Boulton & Cobb (2017) and Lee, Warschauer & Lee (2018) have cast robust results on the benefits of DDL. Boulton & Cobb found average effect sizes of 1.50 for pre/posttest designs and 0.95 for control/experimental designs. Lee, Warschauer & Lee (2018) have reported a medium-sized effect of corpus use on vocabulary learning. Overall, these are medium or large effect sizes that support the use of DDL for language learning. The second claim presents researchers with different angles to exploit, and can possibly be studied using different approaches and foci. Chambers (2005:111) called for further research that looks at ‘the integration of corpora and concordancing in the language-learning environment’, and Pérez-Paredes et al,. (2012:499-500) noted that few studies have examined the interaction of learners with corpora and, as an extension, how learning happens. This study problematized the role of learners as researchers as it was found that only a small percentage of the searches either were effective or showed the minimum levels of sophistication needed to carry out the task at hand.
DDL research has paid considerable attention to measuring the outcomes of learning, but perhaps not so much to what learning and how learning takes place. Lee, Warschauer & Lee (2018) noted that using ‘pre-selected, comprehensible concordance lines appears more effective in supporting their corpus-based activities’ and so does learner-friendly concordancer software specifically designed for L2 learning’, something that had been pointed out in Pérez-Paredes, (2010). An emphasis on technology and tools is manifest. In this talk I will examine one of those angles that need further attention: learning. I will draw on the systematic review of the uses and spread of data-driven learning (DDL) and corpora in language learning and teaching across five major CALL-related journals during the 2011–2015 period in Pérez-Paredes (2019). This review examined 32 research papers published in high rank CALL journals and concluded that the normalization (Bax, 2003) of corpus use in language education has only taken place in a limited number of contexts, mostly in Higher Education, where language teachers and DDL researchers subsume overlapping roles. This finding echoes Boulton´s (2017) call to widen the scope of our research to a more comprehensive spectrum of learning contexts. I will outline a taxonomy of language learning focus, learners´ abilities and processes advocated in the body of research examined that can enhance our understanding of the role played by learning in future data-driven language learning theory or theories.
This talk seeks to contribute to previous work that has tried to bridge the gap between research and practice (Chambers, 2019). I will argue that DDL researchers need to move away from a technology-oriented DDL (Godwin-Jones, 2017) and pursue efforts that widen our understanding of the contributions of DDL to SLA, the contributions of SLA to DDL, and the in-depth analysis of the role of DDL in the broader language learning context, including the use of cognitive strategies (Lee, Warschauer & Lee, 2020).
Pérez-Paredes, P. (2019). A systematic review of the uses and spread of corpora and data-driven learning in CALL research during 2011–2015. Computer Assisted Language Learning.
From Gutiérrez, A., Leder, G. C., & Boero, P. (2016). The Second Handbook of Research on the Psychology of Mathematics Education : The Journey Continues. Brill | Sense.
Noticing and Representing Pattern Structure
Pattern activities have been considered to be one of the main ways for introducing students to algebra (e.g., Ainley, Wilson, & Bills, 2003; Mason, 1996). From this perspective, algebra is about generalizing (Radford, 2006). Previous research has evidenced that visual approaches generated in tasks involving the generalization of geometric figures and numeric sequences can provide strong support for the development of algebraic expressions, variables, and the conceptual framework for functions (Healy & Hoyles, 1999). However, not all activities lead to algebraic thinking. For example, placing the emphasis on the construction of tables of values from pattern sequences can result in the development of closed-form formulas, formulas that students cannot relate to the actual physical situation from which the pattern and tables of values have been generated (e.g., Amit & Neria, 2008; Hino, 2011; Warren, 2005). This impacts on students’ ability to identify the range of equivalent expressions that can be represented by the physical situation.The patterns utilised in the 2005–2015 research encompassed both linear and quadratic functions that were represented as a string of visual figures or numbers. The activities students engaged in involved searching for the relationship between the discernable related units of the pattern (commonly called terms), and the terms’ position in the pattern. These reflect the types of activities predominantly used in current curricula to introduce young adolescent students to the notion of a variable and equivalence.
Students noticing and representing the pattern structure.
Fundamental to patterning activities is the search for mathematical regularities and structures. In this search, Rivera (2013) suggests that students are required to coordinate two abilities, their perceptual ability and their symbolic inferential ability. This coordination involves firstly noticing the commonalities in some given terms, and secondly forming a general concept by noticing the commonality to all terms (Radford, 2006; Rivera, 2013). Finally, students are required to construct and justify their inferred algebraic structure that explains a replicable regularity that could be conveyed as a formula (Rivera, 2013). At this stage the focus is no longer on the terms themselves but rather on the relations across and among them (Kaput, 1995).
Difficulties students experience in noticing pattern structure.
Emerging from the findings of this current research is that while young students are capable of noticing pattern structure and engaging in pattern generalization, they exhibit many of the difficulties found in past research with older students. As revealed in the findings of this research: young students have difficulties moving from one representational system to another such as from the figures themselves to an algebraic form that conveys the relationships between the figures (Becker & Rivera, 2007); students tend to be answer driven as they search for pattern structure (Ma, 2007); they engage in single variational thinking or recursive thinking (Becker & Rivera, 2008; Warren, 2005); they fail to understand algebraic formula (Warren, 2006; Radford, 2006); and, they have difficulties expressing the structure in everyday language (Warren, 2005). In addition, initial representations of the pattern (e.g., pictorial, verbal and symbolic) can influence students’ performance. This is particularly evident as 139 10 and 11 year-old students explored more complex patterns (Stalo, Elia, Gagatsis, Teoklitou, & Savva, 2006), with pictorial representations of patterns proving easier for students to predict terms in further positions and articulate the generalization
Capabilities that assist students to notice structure.
Adding to the research is a delineation of the types of capabilities that assist young students to reach generalizations. The ability to see the invariant relationship between the figural cues is paramount to success (Becker & Rivera, 2006; Stalo et al., 2006). The development of specific language that assists students to describe the pattern (e.g., position, ordinal language, rows) (Warren, Miller, & Cooper, 2011; Warren, 2006) and fluency with using variables (Becker & Rivera, 2006) help students to express and justify their generalization. In addition, Becker and Rivera (2006) found that students who had facility with both figural ability and variable fluency were more capable of noticing the structure, and developing and justifying generalizations. By contrast, students who fail to generalize tend to begin with numerical strategies (e.g., guess and check) as they search for generalizations and lack the flexibility to try other approaches (Becker & Rivera, 2005). This has implications for the types of instructional practices that occur in classroom contexts. It is suggested that instruction that includes verbal, figural and numerical representations of patterns, and emphasises the connections among these representations assists students to reach generalizations (Becker & Rivera, 2006). An ability to think multiplicatively has also been shown to assist students generalize figural representations of linear patterns (Rivera, 2013).
Theories pertaining to noticing structure and reaching generalisations.
Results from Radford’s longitudinal study of 120 8th grade (typically 13–14 year-olds) students over a three year period delineated three types of generalization that emerged from the exploration of figural pattern tasks: factual; contextual; and symbolic (Radford, 2006). The first structural layer is factual: ‘it does not go beyond particular figures, like Figure 1000’. The generalization remains bound at the numerical level. Expressing a generalization as factual does not necessary mean that that is the extent of student’s capability. It may simply be that this level can answer the question posed by others or the context in which algebra is needed (Lozano, 2008). The second layer is contextual; ‘they are contextual in that they refer to contextual embodied objects’ and use language such as the figure and the next figure. Finally, symbolic generalization involves expressing a generalization through alphanumeric symbols. The suggested criteria that can be used to assist teachers to distinguish these levels of early algebraic reasoning are: the presence of entities which have the character of generality; the type of language used; and, the treatment that is applied to these objects based on the application of structural properties (Aké, Godino, Gonzato, & Wilhelmi, 2013). The latter refers to how students express this generality. Aké et al. (2013) suggest that algebraic practice involves two crucial aspects, namely, being able to use literal symbols as a general expression and relate this expression to the visual context from which it is derived. In addition, with growing patterns gesturing between the variables (e.g., pattern term, pattern quantity) in conjunction with having iconic signs to represent both variables (e.g., counters for pattern term and cards for pattern quantity) helped 7–9 year old Indigenous students to identify the pattern structure (Miller & Warren, 2015)
Some references
Boulton, A. (2017). Corpora in language teaching and learning. Language Teaching, 50(4), 483-506.
Boulton, A., & Cobb, T. (2017). Corpus Use in Language Learning: A Meta‐Analysis. Language Learning, 67(2), 348-393.
Chambers, A. (2005). Integrating corpus consultation in language studies. Language Learning & Technology 9(2): 111–125.
Chambers, A. (2019). Towards the corpus revolution? Bridging the research–practice gap. Language Teaching, 52(4), 460-475.
Crossley, S., Kyle, K., and Salsbury, T. 2016. A Usage‐Based Investigation of L2 Lexical Acquisition: The Role of Input and Output. Modern Language Journal 100.3, 702-15.
Flowerdew, L. (2009). Applying corpus linguistics to pedagogy: A critical evaluation. International Journal of Corpus Linguistics, 14(3), 393-417.
Gillespie, J. (2020). CALL research: Where are we now? ReCALL,32(2), 127-144. doi:10.1017/S0958344020000051
Godwin-Jones, R. (2017). Data-informed language learning. Language Learning & Technology, 21(3), 9–27.
Gutiérrez, A., Leder, G. C., & Boero, P. (2016). The Second Handbook of Research on the Psychology of Mathematics Education : The Journey Continues. Brill :Sense
Johansson, S. (2009). Some thoughts on corpora and second-language acquisition. In Aijmer, K. (Ed.). Corpora and language teaching. John Benjamins Publishing, 33-44.
Lee, H., Warschauer, M., & Lee, J. H. (2018). The Effects of Corpus Use on Second Language Vocabulary Learning: A Multilevel Meta-analysis. Applied Linguistics.
Lee, H., Warschauer, M., & Lee, J. H. (2020). Toward the Establishment of a Data‐Driven Learning Model: Role of Learner Factors in Corpus‐Based Second Language Vocabulary Learning. The Modern Language Journal.
Leung, C., & Scarino, A. (2016). Reconceptualizing the nature of goals and outcomes in language/s education. The Modern Language Journal, 100(S1), 81-95.
Long, M. H. (1991). Focus on form: A design feature in language teaching methodology. Foreign language research in cross-cultural perspective, 2(1), 39-52.
Ortega, L. (2014). Ways forward for a bi/multilingual turn in SLA. In S. May (Ed.), The multilingual turn: Implications for SLA, TESOL, and bilingual education (pp. 32-53). New York: Routledge.
Pérez-Paredes, P. (2010). Corpus linguistics and language education in perspective: Appropriation and the possibilities scenario. In Harris, T., & Jaén, M. M. (Eds.). Corpus linguistics in language teaching. Peter Lang, 53-73.
Pérez-Paredes, Pascual, María Sánchez-Tornel, Jose María Alcaraz Calero, and Pilar Aguado Jiménez. (2011). Tracking Learners’ Actual Uses of Corpora: Guided vs Non-guided Corpus Consultation. Computer Assisted Language Learning 24.3, 233-53.
Perez-Paredes, P. eta al. (2012). Learners Search Patterns during Corpus-based Focus-on-form Activities: A Study on Hands-on Concordancing. International Journal of Corpus Linguistics 17.4, 482-515.
Pérez-Paredes, P. (2019). A systematic review of the uses and spread of corpora and data-driven learning in CALL research during 2011–2015. Computer Assisted Language Learning.
Pérez-Paredes, P., Sánchez-Tornel, M. and Alcaraz Calero, J.M. (2012) Learners’ search patterns during corpus-based focus-on-form activities. A study on hands-on concordancing. International Journal of Corpus Linguistics 17:4, 482–515.
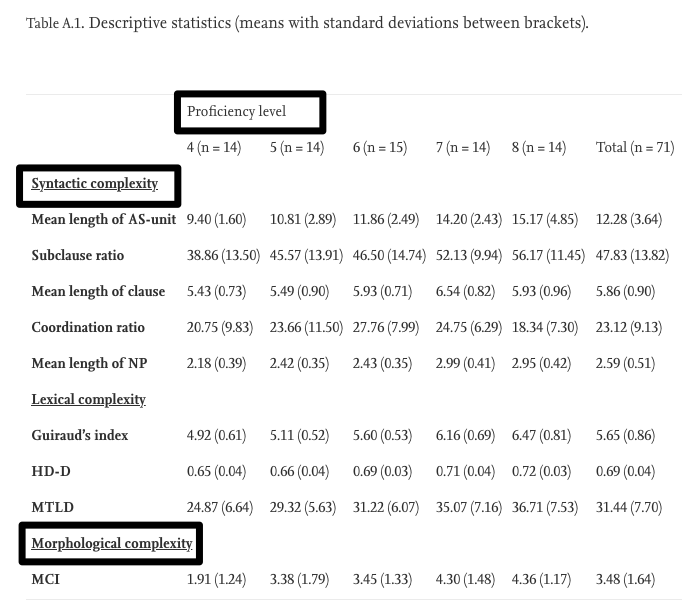
This study investigates the relationship between nine quantitative measures of L2 speech complexity and subjectively rated L2 proficiency by comparing the oral productions of English L2 learners at five IELTS proficiency levels. We carry out ANOVAs with pairwise comparisons to identify differences between proficiency levels, as well as ordinal logistic regression modelling, allowing us to combine multiple complexity dimensions in a single analysis. The results show that for eight out of nine measures, targeting syntactic, lexical and morphological complexity, a significant overall effect of proficiency level was found, with measures of lexical diversity (i.e. Guiraud’s index and HD-D), overall syntactic complexity (mean length of AS-unit), phrasal elaboration (mean length of noun phrase) and morphological richness (morphological complexity index) showing the strongest association with proficiency level. Three complexity measures emerged as significant predictors in our logistic regression model, each targeting different linguistic dimensions: Guiraud’s index, the subordination ratio and the morphological complexity index.
Conclusion
The present study on the relationship between nine complexity measures and five different levels of oral proficiency, as measured by the IELTS speaking test, confirms previous studies which have found that learners at higher levels of proficiency tend to produce more complex language. Even though we found higher complexity scores in higher proficiency levels for measures of lexical, syntactic and morphological complexity, the observed patterns differ substantially across measures. If we only consider differences between adjacent proficiency levels, we observed a significant increase in morphological richness (as measured by the morphological complexity index) between levels 4 and 5, in lexical diversity (Guiraud’s index) between levels 5 and 6, and in overall syntactic (mean length of AS-unit), clausal (mean length of clause) and phrasal complexity (mean length of noun phrase) as well as lexical diversity (Guiraud’s index and HD-D) between levels 6 and 7. We did not observe significant differences in complexity between the highest two proficiency levels in our dataset (i.e. 7 and 8). In addition, we found that the Guiraud index, the subclause ratio and the morphological complexity index applied to verbs were significant predictors for proficiency level in our ordinal logistic regression model, explaining around two thirds of the variance in proficiency level.
Crossley, S. (2020). Linguistic features in writing quality and development: An overview. Journal of Writing Research, 11(3).
Abstract
This paper provides an overview of how analyses of linguistic features in writing samples provide a greater understanding of predictions of both text quality and writer development and links between language features within texts. Specifically, this paper provides an overview of how language features found in text can predict human judgements of writing proficiency and changes in writing levels in both cross-sectional and longitudinal studies. The goal is to provide a better understanding of how language features in text produced by writers may influence writing quality and growth. The overview will focus on three main linguistic construct (lexical sophistication, syntactic complexity, and text cohesion) and their interactions with quality and growth in general. The paper will also problematize previous research in terms of context, individual differences, and reproducibility.
Conclusion
While there are a number of potential limitations to linguistic analyses of writing, advanced NLP tools and programs have begun to address linguistic complications while better data collection methods and more robust statistical and machine learning approaches can help to control for confounding variables such as first language differences, prompt effects, and variation at the individual level. This means that we are slowly gaining a better understanding of interactions between linguistic production and text quality and writing development across multiple types of writers, tasks, prompts, and disciplines. Newer studies are beginning to also look at interaction between linguistic features in text (product measures) and writing process characteristics such as fluency (bursts), revisions (deletions and insertions) or source use (Leijten & Van Waes, 2013; Ranalli, Feng, Sinharry, & Chukharev-Hudilainen, 2018; Sinharay, Zhang, & Deane, 2019). Future work on the computational side may address concerns related to the accuracy of NLP tools, the classification of important discourse structures such as claims and arguments, and eventually even predictions of argumentation strength, flow, and style. Importantly, we need not wait for the future because linguistic text analyses have immediate applications in automatic essay scoring (AES) and automatic writing evaluation (AWE), both of which are becoming more common and can have profound effects on the teaching and learning of writing skills. Current issues for both AES and AWE involve both model reliability (Attali & Burstein, 2006; Deane, Williams, Weng, & Trapani, 2013; Perelman, 2014) and construct validity (Condon, 2013; Crusan, 2010; Deane et al., 2013; Elliot et al., 2013, Haswell, 2006; Perelman, 2012), but more principled analyses of linguistic feature, especially those that go beyond words and structures, are helping to alleviate those concern and should only improve over time. That being said, the analysis of linguistic features in writing can help us not only better understand writing quality and development but also improve the teaching and learning of writing skills and strategies.
Díez-Bedmar, M. B., & Pérez-Paredes, P. (2020). Noun phrase complexity in young Spanish EFL learners’ writing: Complementing syntactic complexity indices with corpus-driven analyses. International Journal of Corpus Linguistics, 25(1), 4-35.
Abstract
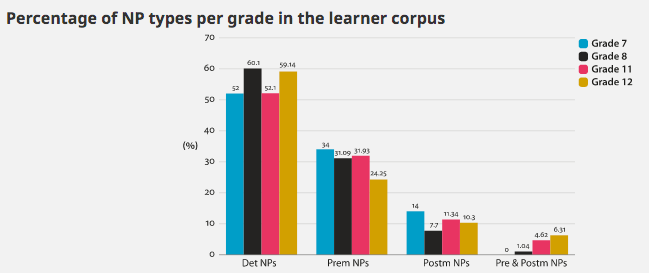
he research reported in this article examines Noun Phrase (NP) syntactic complexity in the writing of Spanish EFL secondary school learners in Grades 7, 8, 11 and 12 in the International Corpus of Crosslinguistic Interlanguage. Two methods were combined: a manual parsing of NPs and an automatic analysis of NP indices using the Tool for the Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC). Our results revealed that it is in premodifying slots that syntactic complexity in NPs develops. We argue that two measures, (i) nouns and modifiers (a syntactic complexity index) and (ii) determiner + multiple premodification + head (a NP type obtained as a result of a corpus-driven analysis), can be used as indices of syntactic complexity in young Spanish EFL learner language development. Besides offering a learner-language-driven taxonomy of NP syntactic complexity, the paper underscores the strength of using combined methods in SLA research.
Conclusion
Our research highlights the need for using combined methods of analysis that examine the same data from different perspectives. The use of statistical complexity analysis software (Kyle, 2016) has allowed us to account for every single noun and nominal group in the corpus. The range of indices in Kyle (2016) has allowed us to approach syntactic phenomena from a purely quantitative perspective. As a result, we have found that the use of the “Nouns as modifiers” index yields significant differences between Grades 8 and 12, which confirms our finding that premodification slots are of interest for the study of learner language development. The corpus-driven manual analysis of NPs, in turn, has allowed us to gain an in-depth understanding of the types of complexity patterns used by learners in the different grades. As a result of this approach, our research has produced a learner-generated taxonomy of NP syntactic complexity that can be used in studies that examine learner language in other contexts. By combining these two research methods, we hope to make a case for their integration and to enrich methodological pluralism (McEnery & Hardie, 2012; Römer, 2016). Moreover, the findings obtained with the two methods are consistent and thus show promising avenues for collaboration and complementarity.
Two methodological features of this study are worth considering. The fine-grained classification of NP types, which includes every NP type found in the corpus, may have determined the results of the statistical analysis: the more detailed the classification of NP, the more likely it is to obtain a low number of instances in some of the NP types. Another feature to be considered is that the manual parsing conducted did not include every single noun in the corpus. This may be seen as a limitation of this study. Another limitation lies in the use of automatic analysis software and POS tagging that was not written primarily to navigate learner language. The impact of these systems on learner-language analysis has rarely been explored in corpus linguistics, and we believe that these software solutions should be sensitive to the range of disfluencies of learner language. If the small number of errors found in the use of automatic tools in learner language are considered tolerable, the automatic analysis of complexity and frequency indices in learner language can be beneficial. Finally, this study has not offered a Contrastive Interlanguage Analysis (CIA) (Granger, 1996, 2015) as it is beyond the scope of this paper to look at other L1 learners or English as an L1.
Khushik, G. A., & Huhta, A. (2019). Investigating Syntactic Complexity in EFL Learners’ Writing across Common European Framework of Reference Levels A1, A2, and B1. Applied Linguistics.
Abstract
The study investigates the linguistic basis of Common European Framework of Reference (CEFR) levels in English as a foreign language (EFL) learners’ writing. Specifically, it examines whether CEFR levels can be distinguished with reference to syntactic complexity (SC) and whether the results differ between two groups of EFL learners with different first languages (Sindhi and Finnish). This sheds light on the linguistic comparability of the CEFR levels across L1 groups. Informants were teenagers from Pakistan (N = 868) and Finland (N = 287) who wrote the same argumentative essay that was rated on a CEFR-based scale. The essays were analysed for 28 SC indices with the L2 Syntactic Complexity Analyzer and Coh-Metrix. Most indices were found to distinguish CEFR levels A1, A2, and B1 in both language groups: the clearest separators were the length of production units, subordination, and phrasal density indices. The learner groups differed most in the length measures and phrasal density when their CEFR level was controlled for. However, some indices remained the same, and the A1 level was more similar than A2 and B2 in terms of SC across the two groups.
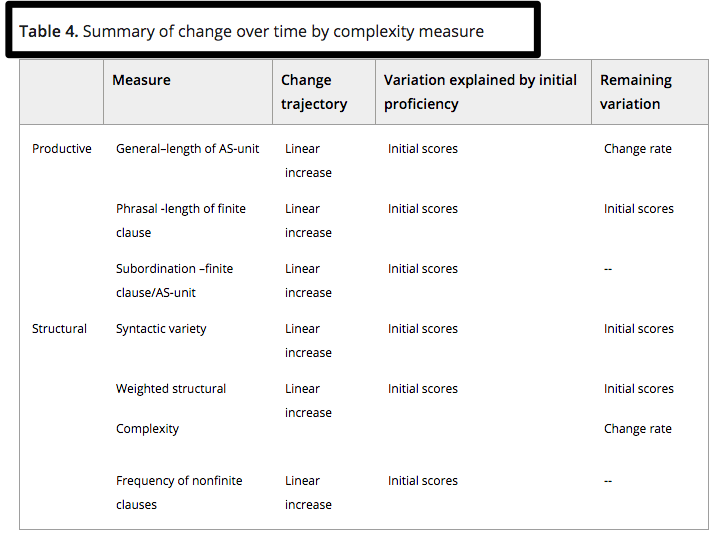
This paper examines the development and variation of syntactic complexity in the speech of 66 L2 learners over three academic semesters in an intensive English program. This investigation tracked development using hierarchical linear modeling with three commonly‐used, recommended measures of productive complexity (i.e., length of AS‐unit, clause length, subordination) and three exploratory measures of structural complexity (i.e., syntactic variety, weighted complexity scores, frequency of nonfinite clauses) to capture different aspects of syntactic complexity. All measures showed growth over time, suggesting that learners are not forced to prioritize certain aspects of the construct at the expense of others (i.e., no trade‐off effects) across development. The unexplained significant variation found in these data differed among the measures reinforcing notions of multidimensionality of linguistic complexity.
Conclusion
The results can inform the measurement choices and methodology for future English L2 research. As would be expected with language learning performance, there was substantial variation. L2 researchers likely want to use practical measures that capture the variation between individuals and across development. The variation in different parts of the measure’s models suggest that the measures capture separate aspects of complexity, and some suggestions can be offered. Subordination may serve as a practical, broad measure of complexity in instructed contexts. The easily calculated phrasal complexity revealed variation early in development, as did the weighted structural complexity measure. Moreover, researchers may want to consider using the weighted complexity measure for research investigating individual differences in language performance. One possibility is to create a measure based on standard deviation (e.g., De Clercq & Housen, 2017) of the weighted complexity measure, if the study’s purpose is to measure the variety of structural complexity in the language sample, rather than the growth of the developmentally‐aligned structural complexity. When investigating differences in language learning outcomes, general complexity and the weighted structural complexity may be useful, given the additional variation found in the models. The unexplained significant remaining variation between individuals is fodder for future longitudinal research. For instance, future research might consider how production may be influenced by the frequency and function of constructions in learners’ L1s, motivation (Verspoor & Behrens, 2011), or individual speaking style (Pallotti, 2009). Overall, this paper offers a unique comparison of syntactic complexity, both productive and structural complexity measures, advancing our understanding of this most complex construct of language performance.
Speaker: Tove Larsson, Uppsala University, Sweden; Un. Catholique Louvain, BelgiumTitle: On Learner Corpus Research and things I wish someone had told me when I was a grad student
Speaker: Tyle True, Northern Arizona University, USATitle: Do you know how fast you were going?: Learning about the language of U.S. traffic stops to help L2 English
Speaker: Viviana Cortes, Georgia State University, USATitle: Lexical bundles as building blocks in discourse: the case of 3-word bundles
Speaker: Joe Collentine, Northern Arizona University, USATitle: Corpus research in the acquisition of Spanish as an L2
Speaker: Larissa Goulart, Northern Arizona University, USATitle: Second language writing for University purposes: From learner, to teacher, to researcher
Speaker: Ana Bocorny, Federal University of Rio Grande do Sul, BrazilTitle: Writing scientific articles with the support of key lexical bundles: a corpus-driven study in the area of health sciences
Speaker: Deise P. Dutra, Federal University of Minas Gerais, BrazilTitle: Language use: Corpus linguistics informing the language classroom
Speaker: Carolina Zuppardi, Laureate Digital and Pontifical Catholic University of Sao Paulo, BrazilTitle: Collocation dimensions in academic English






{kind=link}
{kind=link}