This research explores the POS-tag sequences that shape the transition from upper intermediate (B2 CEFR) to near-native proficiency (C2 CEFR) in a corpus of essays (n=32,410) from the Cambridge Learner Corpus. Gilquin (2018) and others have shown that POS tag sequences offer a holistic approach to extracting the most commonly used patterns without a starting point of an a prioriset of words and word sequences. Using corpus linguistics informed by usage-based theories of language learning, this paper examines the frequency and distribution of 4-slot POS-tag sequences in L2 English writing, drawing on the taxonomy of pattern grammar (Francis et al. 1996, 1998; Hunston & Francis, 2000). Findings point to the presence of both core and emergent POS-tag sequences in learner language in the two proficiency levels analysed. These sequences point to the presence of dynamic language restructuring processes as learners become more proficient and re-evaluate their understanding of frequency and distribution in English. This paper shows evidence of how language competence increases with proficiency. The research offers new evidence to our understanding of the development of L2 writing in EFL contexts.
Lim, J., Mark, G., Pérez-Paredes, P. & O’Keeffe, A. (2024). Exploring Part of Speech (POS)-tag sequences in a large-scale learner corpus of L2 English: A developmental perspective. Corpora, 19(1).
The following is an extract form Hunston (2022, p. 256).
Hunston, S. (2022). Corpora in applied linguistics. Cambridge University Press.
Sinclair made a number of generalisations in the 1980s (Sinclair 1991, 2004; see also Francis 1993; Hoey 2005; Hunston 2002; Stubbs 2001) which might be summarised as follows:
• In describing the meanings of a word, the ‘phrases’ that the word is used in are central to that description (= there is no distinction between form and meaning).
• Those ‘phrases’ are neither fully fixed nor fully open – in fact the distinction between ‘word’ and ‘fixed phrase’ does not hold up; the boundaries of a ‘phrase’ may be indeterminate and the variation resists classification.
• Those ‘phrases’ incorporate associations between individual words that might be discussed under the heading of collocation, but the ‘phrases’ also include aspects of grammar and commonalities of meaning rather than of form (= language is not divided into lexis and grammar).
• Although we commonly think of words as having meaning, and we often talk of a word having several meanings, what actually happens is that a word occurs in several ‘phrases’ and meaning resides in the ‘phrase’ rather than the word (= unit of meaning).
• When we look at text we can observe that a lot of it can be explained as a series of units of meaning and the remainder can be explained in terms of residual grammar (= idiom principle and open-choice principle).
The Corpus of North American Spoken English (CoNASE), a 1.25-billion-word corpus of geolocated automatic speech-to-text transcripts, is now available in a beta version.
The corpus was created from 301,847 ASR transcripts from 2,572 YouTube channels, corresponding to 154,041 hours of video. The size of the corpus is 1,252,066,371 word tokens.
The channels sampled in the corpus are associated with local government entities such as town, city, or county boards and councils, school or utility districts, regional authorities such as provincial or territorial governments, or other governmental organizations.
The transcripts are primarily of recordings of public meetings, although other genres are also present. Video transcripts have been assigned exact latitude-longitude coordinates using a geocoding script.
This information was distributed through the Corpora-List by Steven Coats, University of Oulu, Finland
To cite the corpus, please use
Coats, Steven. 2021. Corpus of North American Spoken English (CoNASE). http://cc.oulu.fi/~scoats/CoNASE.html.
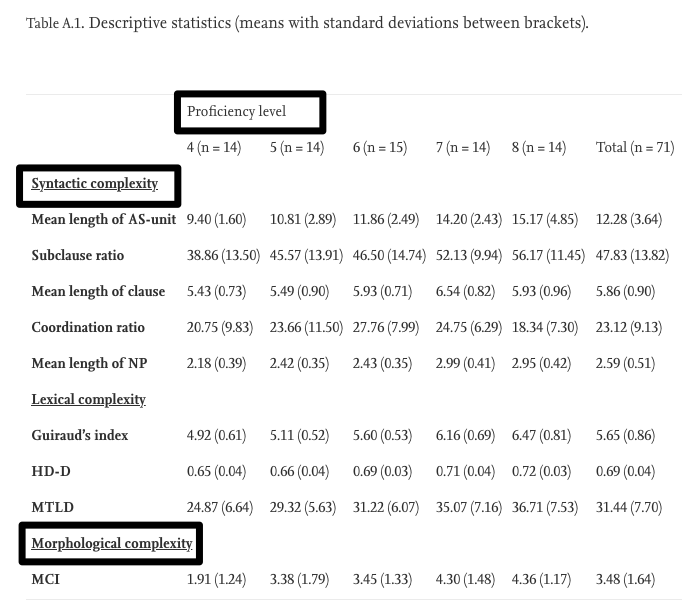
This study investigates the relationship between nine quantitative measures of L2 speech complexity and subjectively rated L2 proficiency by comparing the oral productions of English L2 learners at five IELTS proficiency levels. We carry out ANOVAs with pairwise comparisons to identify differences between proficiency levels, as well as ordinal logistic regression modelling, allowing us to combine multiple complexity dimensions in a single analysis. The results show that for eight out of nine measures, targeting syntactic, lexical and morphological complexity, a significant overall effect of proficiency level was found, with measures of lexical diversity (i.e. Guiraud’s index and HD-D), overall syntactic complexity (mean length of AS-unit), phrasal elaboration (mean length of noun phrase) and morphological richness (morphological complexity index) showing the strongest association with proficiency level. Three complexity measures emerged as significant predictors in our logistic regression model, each targeting different linguistic dimensions: Guiraud’s index, the subordination ratio and the morphological complexity index.
Conclusion
The present study on the relationship between nine complexity measures and five different levels of oral proficiency, as measured by the IELTS speaking test, confirms previous studies which have found that learners at higher levels of proficiency tend to produce more complex language. Even though we found higher complexity scores in higher proficiency levels for measures of lexical, syntactic and morphological complexity, the observed patterns differ substantially across measures. If we only consider differences between adjacent proficiency levels, we observed a significant increase in morphological richness (as measured by the morphological complexity index) between levels 4 and 5, in lexical diversity (Guiraud’s index) between levels 5 and 6, and in overall syntactic (mean length of AS-unit), clausal (mean length of clause) and phrasal complexity (mean length of noun phrase) as well as lexical diversity (Guiraud’s index and HD-D) between levels 6 and 7. We did not observe significant differences in complexity between the highest two proficiency levels in our dataset (i.e. 7 and 8). In addition, we found that the Guiraud index, the subclause ratio and the morphological complexity index applied to verbs were significant predictors for proficiency level in our ordinal logistic regression model, explaining around two thirds of the variance in proficiency level.
Crossley, S. (2020). Linguistic features in writing quality and development: An overview. Journal of Writing Research, 11(3).
Abstract
This paper provides an overview of how analyses of linguistic features in writing samples provide a greater understanding of predictions of both text quality and writer development and links between language features within texts. Specifically, this paper provides an overview of how language features found in text can predict human judgements of writing proficiency and changes in writing levels in both cross-sectional and longitudinal studies. The goal is to provide a better understanding of how language features in text produced by writers may influence writing quality and growth. The overview will focus on three main linguistic construct (lexical sophistication, syntactic complexity, and text cohesion) and their interactions with quality and growth in general. The paper will also problematize previous research in terms of context, individual differences, and reproducibility.
Conclusion
While there are a number of potential limitations to linguistic analyses of writing, advanced NLP tools and programs have begun to address linguistic complications while better data collection methods and more robust statistical and machine learning approaches can help to control for confounding variables such as first language differences, prompt effects, and variation at the individual level. This means that we are slowly gaining a better understanding of interactions between linguistic production and text quality and writing development across multiple types of writers, tasks, prompts, and disciplines. Newer studies are beginning to also look at interaction between linguistic features in text (product measures) and writing process characteristics such as fluency (bursts), revisions (deletions and insertions) or source use (Leijten & Van Waes, 2013; Ranalli, Feng, Sinharry, & Chukharev-Hudilainen, 2018; Sinharay, Zhang, & Deane, 2019). Future work on the computational side may address concerns related to the accuracy of NLP tools, the classification of important discourse structures such as claims and arguments, and eventually even predictions of argumentation strength, flow, and style. Importantly, we need not wait for the future because linguistic text analyses have immediate applications in automatic essay scoring (AES) and automatic writing evaluation (AWE), both of which are becoming more common and can have profound effects on the teaching and learning of writing skills. Current issues for both AES and AWE involve both model reliability (Attali & Burstein, 2006; Deane, Williams, Weng, & Trapani, 2013; Perelman, 2014) and construct validity (Condon, 2013; Crusan, 2010; Deane et al., 2013; Elliot et al., 2013, Haswell, 2006; Perelman, 2012), but more principled analyses of linguistic feature, especially those that go beyond words and structures, are helping to alleviate those concern and should only improve over time. That being said, the analysis of linguistic features in writing can help us not only better understand writing quality and development but also improve the teaching and learning of writing skills and strategies.
Díez-Bedmar, M. B., & Pérez-Paredes, P. (2020). Noun phrase complexity in young Spanish EFL learners’ writing: Complementing syntactic complexity indices with corpus-driven analyses. International Journal of Corpus Linguistics, 25(1), 4-35.
Abstract
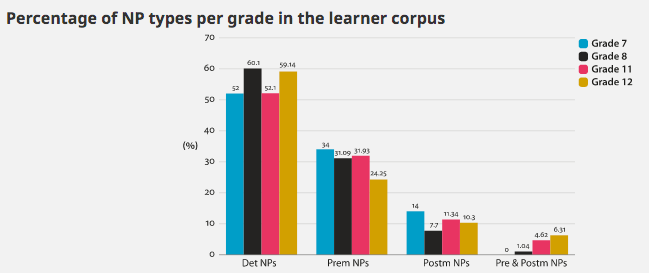
he research reported in this article examines Noun Phrase (NP) syntactic complexity in the writing of Spanish EFL secondary school learners in Grades 7, 8, 11 and 12 in the International Corpus of Crosslinguistic Interlanguage. Two methods were combined: a manual parsing of NPs and an automatic analysis of NP indices using the Tool for the Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC). Our results revealed that it is in premodifying slots that syntactic complexity in NPs develops. We argue that two measures, (i) nouns and modifiers (a syntactic complexity index) and (ii) determiner + multiple premodification + head (a NP type obtained as a result of a corpus-driven analysis), can be used as indices of syntactic complexity in young Spanish EFL learner language development. Besides offering a learner-language-driven taxonomy of NP syntactic complexity, the paper underscores the strength of using combined methods in SLA research.
Conclusion
Our research highlights the need for using combined methods of analysis that examine the same data from different perspectives. The use of statistical complexity analysis software (Kyle, 2016) has allowed us to account for every single noun and nominal group in the corpus. The range of indices in Kyle (2016) has allowed us to approach syntactic phenomena from a purely quantitative perspective. As a result, we have found that the use of the “Nouns as modifiers” index yields significant differences between Grades 8 and 12, which confirms our finding that premodification slots are of interest for the study of learner language development. The corpus-driven manual analysis of NPs, in turn, has allowed us to gain an in-depth understanding of the types of complexity patterns used by learners in the different grades. As a result of this approach, our research has produced a learner-generated taxonomy of NP syntactic complexity that can be used in studies that examine learner language in other contexts. By combining these two research methods, we hope to make a case for their integration and to enrich methodological pluralism (McEnery & Hardie, 2012; Römer, 2016). Moreover, the findings obtained with the two methods are consistent and thus show promising avenues for collaboration and complementarity.
Two methodological features of this study are worth considering. The fine-grained classification of NP types, which includes every NP type found in the corpus, may have determined the results of the statistical analysis: the more detailed the classification of NP, the more likely it is to obtain a low number of instances in some of the NP types. Another feature to be considered is that the manual parsing conducted did not include every single noun in the corpus. This may be seen as a limitation of this study. Another limitation lies in the use of automatic analysis software and POS tagging that was not written primarily to navigate learner language. The impact of these systems on learner-language analysis has rarely been explored in corpus linguistics, and we believe that these software solutions should be sensitive to the range of disfluencies of learner language. If the small number of errors found in the use of automatic tools in learner language are considered tolerable, the automatic analysis of complexity and frequency indices in learner language can be beneficial. Finally, this study has not offered a Contrastive Interlanguage Analysis (CIA) (Granger, 1996, 2015) as it is beyond the scope of this paper to look at other L1 learners or English as an L1.
Khushik, G. A., & Huhta, A. (2019). Investigating Syntactic Complexity in EFL Learners’ Writing across Common European Framework of Reference Levels A1, A2, and B1. Applied Linguistics.
Abstract
The study investigates the linguistic basis of Common European Framework of Reference (CEFR) levels in English as a foreign language (EFL) learners’ writing. Specifically, it examines whether CEFR levels can be distinguished with reference to syntactic complexity (SC) and whether the results differ between two groups of EFL learners with different first languages (Sindhi and Finnish). This sheds light on the linguistic comparability of the CEFR levels across L1 groups. Informants were teenagers from Pakistan (N = 868) and Finland (N = 287) who wrote the same argumentative essay that was rated on a CEFR-based scale. The essays were analysed for 28 SC indices with the L2 Syntactic Complexity Analyzer and Coh-Metrix. Most indices were found to distinguish CEFR levels A1, A2, and B1 in both language groups: the clearest separators were the length of production units, subordination, and phrasal density indices. The learner groups differed most in the length measures and phrasal density when their CEFR level was controlled for. However, some indices remained the same, and the A1 level was more similar than A2 and B2 in terms of SC across the two groups.
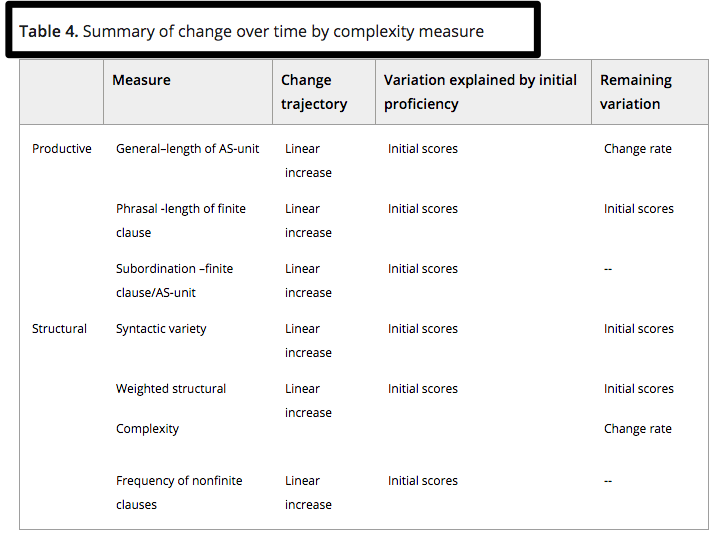
This paper examines the development and variation of syntactic complexity in the speech of 66 L2 learners over three academic semesters in an intensive English program. This investigation tracked development using hierarchical linear modeling with three commonly‐used, recommended measures of productive complexity (i.e., length of AS‐unit, clause length, subordination) and three exploratory measures of structural complexity (i.e., syntactic variety, weighted complexity scores, frequency of nonfinite clauses) to capture different aspects of syntactic complexity. All measures showed growth over time, suggesting that learners are not forced to prioritize certain aspects of the construct at the expense of others (i.e., no trade‐off effects) across development. The unexplained significant variation found in these data differed among the measures reinforcing notions of multidimensionality of linguistic complexity.
Conclusion
The results can inform the measurement choices and methodology for future English L2 research. As would be expected with language learning performance, there was substantial variation. L2 researchers likely want to use practical measures that capture the variation between individuals and across development. The variation in different parts of the measure’s models suggest that the measures capture separate aspects of complexity, and some suggestions can be offered. Subordination may serve as a practical, broad measure of complexity in instructed contexts. The easily calculated phrasal complexity revealed variation early in development, as did the weighted structural complexity measure. Moreover, researchers may want to consider using the weighted complexity measure for research investigating individual differences in language performance. One possibility is to create a measure based on standard deviation (e.g., De Clercq & Housen, 2017) of the weighted complexity measure, if the study’s purpose is to measure the variety of structural complexity in the language sample, rather than the growth of the developmentally‐aligned structural complexity. When investigating differences in language learning outcomes, general complexity and the weighted structural complexity may be useful, given the additional variation found in the models. The unexplained significant remaining variation between individuals is fodder for future longitudinal research. For instance, future research might consider how production may be influenced by the frequency and function of constructions in learners’ L1s, motivation (Verspoor & Behrens, 2011), or individual speaking style (Pallotti, 2009). Overall, this paper offers a unique comparison of syntactic complexity, both productive and structural complexity measures, advancing our understanding of this most complex construct of language performance.