TIA 2015: FIRST CALL FOR PAPERS
—————————————————–
Terminology and Artificial Intelligence 2015
4 November – 6 November 2015
University of Granada, Spain
http://lexicon.ugr.es/tia2015/Home.html
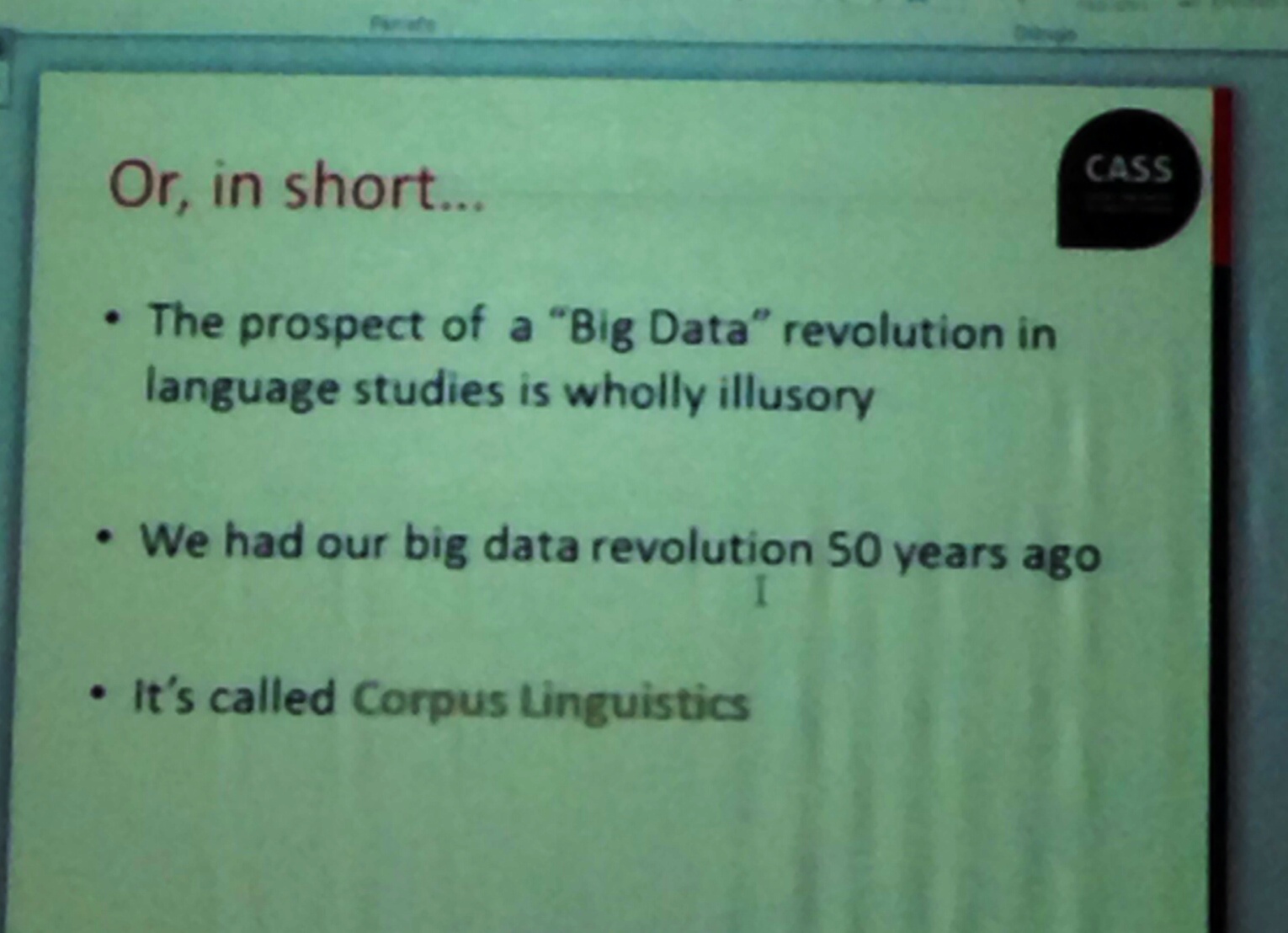
Terminology and Artificial Intelligence (TIA) 2015 will highlight the close connection between multilingual terminology, ontologies, and the representation of specialized knowledge. Knowledge, as regarded in Terminology, is something more complex than a simple hierarchy or a thesaurus-like structure. In this sense, ontologies, understood as a shared conceptualization of a domain that can be communicated between people and/or systems, are better suited for accounting for multilinguality and contextual constraints. The link between Terminology and knowledge representation has been widely acknowledged with the advent of multilingual ontologies.
This is particularly relevant since today’s networked society has generated an increasing number of contexts where multilingualism challenges current knowledge representation methods and techniques. To meet these challenges, it is necessary to deal with semantics since information can be organized, presented, and searched, based on meaning and not just text. Ideally, this would mean that language-independent specialized knowledge could be accessed across different natural languages. There is thus the urgent need for high-quality multilingual knowledge resources that are able to bridge communication barriers, and which can be linked and shared.
Such issues can only be successfully addressed with creative collaborative solutions within disciplines, such as knowledge engineering, terminology, ontology engineering, cognitive sciences, corpus lexicology, and computational linguistics. Accordingly, the TIA 2015 Conference will provide a forum for interdisciplinary research that focuses on the intersection of different disciplines dealing with terminology, multilingualism, lexicology, ontology, and knowledge representation. Papers may address both theoretical questions and methodological aspects on these issues, as well as interdisciplinary approaches developed to facilitate convergence and co-operation in terminological aspects of importance to an increasingly multilingual society.
TIA 2015 solicits both regular papers (8 pages), which present significant work, and short papers (4 pages), which typically present work in progress or a smaller, focused contribution. Regardless of the language of the paper( English, Spanish, or French), all paper presentations will be in English. The submission deadline is June 15. See the conference webpage for more specific submission details.
TOPICS
1. Terminology and ontology acquisition and management
· Applying pattern recognition to enriching terminological resource
· Lexicons, thesauri and ontologies as semantic resources
· Lexicons and ontologies as means for knowledge transfer
· Reusing, standardizing and merging terminological or ontological resources
· Multilingual terminology extraction
· Multilinguality and multimodality in terminological resources
· Management of language resources
1. Terminology and knowledge representation
· Ontological semantics and linguistic
· Ontology localization
· Development of multimedia terminological resources
· Terminology alignment in parallel corpora and other lexical resources
· Representation of terms and conceptual relations in knowledge-based applications
· Comparative studies of terminological resources and/or ontological resources
· Terminological resources in the 21st century
· Harmonization of format and standards in terminological resources
1. Terminology and ontologies for applications
· Interoperability and reusability in knowledge-based tools and applications
· Models and metamodels in annotating semantic and terminological resources
· New R&D directions in terminology for industrial uses and needs
· Terminology for machine translation and natural language processing
Featured plenary speakers
Paul Buitelaar, National University of Ireland, Galway, Ireland
Ricardo Miral Usón, Universidad Nacional de Educación a Distancia (UNED), Madrid, Spain
TIA 2015 CHAIRS
Pamela Faber, University of Granada
Thierry Poibeau, CNRS
The PROGRAMME COMMITTEE members are distinguished experts from all over the world.
SUBMISSION INFORMATION
See the TIA 2015 website: http://lexicon.ugr.es/tia2015/Submission.html
IMPORTANT DATES
Paper submissions (long and short papers): 15 June 2015
Notification to authors: 4 September 2015
Final camera-ready paper: 24 September 2015
Conference: 4-6 November 2015
VENUE:
University of Granada,
Faculty of Translation and Interpreting,
18071 Granada, Spain
Contact information: termai2015@gmail.com
Mensaje distribuido a través de la lista de (AESLA)