CLAWS7 tagset on Sketch Engine
European Union Language Resources in Sketch Engine
| By Paulo Martins. University of Mihno, Braga, 11/11/2021 |
Learning a programming language
Coding literacy
Learning a programming language is easier than learning a natural language (?), explore new scientific strategies, automate daily tasks, boost problem solving skills.
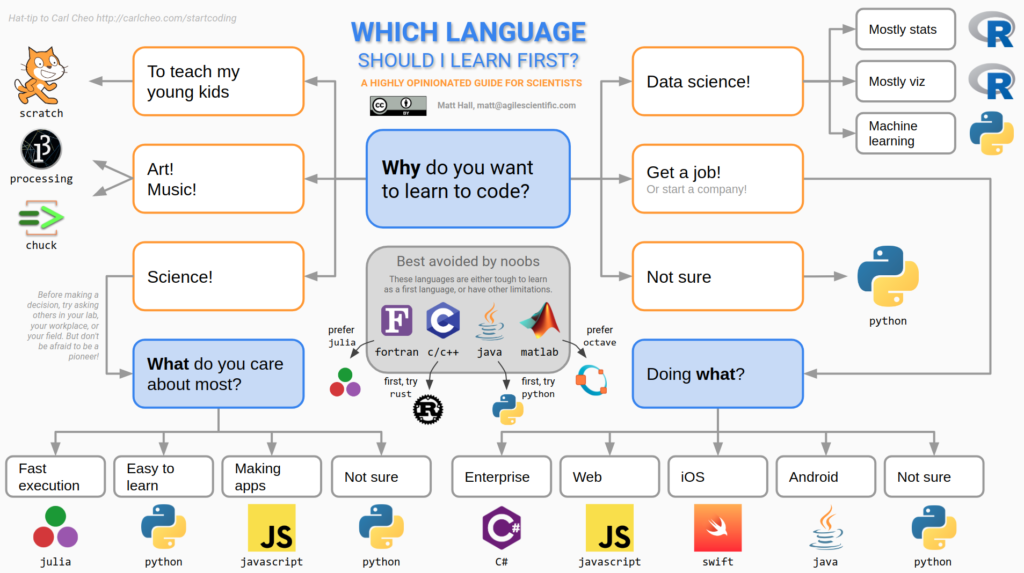
NLP and data science
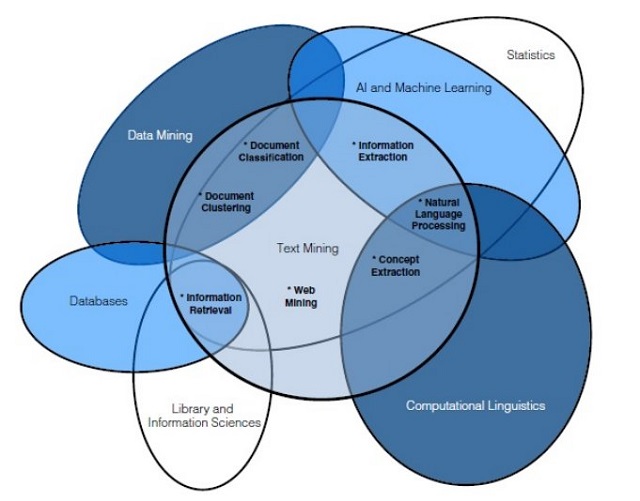
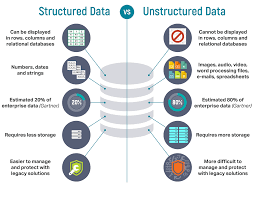
Data: raw, unstructured vs information: structured, organized…useful.
Some tools
Webcrawlers: fetching comments is challenging (javascript and stuff)
Json files Json syntax
YAGO is a knowledge base, i.e., a database with knowledge about the real world. YAGO contains both entities (such as movies, people, cities, countries, etc.) and relations between these entities (who played in which movie, which city is located in which country, etc.). All in all, YAGO contains more than 50 million entities and 2 billion facts.
YAGO arranges its entities into classes: Elvis Presley belongs to the class of people, Paris belongs to the class of cities, and so on. These classes are arranged in a taxonomy: The class of cities is a subclass of the class of populated places, this class is a subclass of geographical locations, etc.
YAGO also defines which relations can hold between which entities: birthPlace, e.g., is a relation that can hold between a person and a place. The definition of these relations, together with the taxonomy is called the ontology.
SPARQL, GraphDB
This information from corpora-bounces@uib.no
SyntagNet, a resource with 88,000 lexical-semantic combinations, is now out!
We
are proud to announce that SyntagNet 1.0 (http://syntagnet.org)
is now available for download at http://syntagnet.org/download.
Developed at the Sapienza NLP group (http://nlp.uniroma1.it),
the multilingual Natural Language Processing group at the Sapienza University of Rome, SyntagNet is a
manually-curated large-scale lexical-semantic combination database which associates pairs of concepts with pairs of co-occurring words. The goal of SyntagNet is to capture sense distinctions evoked by
syntagmatic relations (e.g. mouse.n.1 and squeak.v.1 vs mouse.n.2 and click.n.4), hence providing information which
complements the essentially paradigmatic knowledge shared by currently available Lexical Knowledge Bases such as WordNet. Its main features are:
And much more! Please check out our EMNLP 2019 paper:
M. Maru, F. Scozzafava, F. Martelli, R. Navigli. SyntagNet: Challenging Supervised Word Sense Disambiguation with Lexical-Semantic Combinations, Proc. of EMNLP-IJCNLP 2019
or
http://syntagnet.org
for more details!
SyntagRank,
a state-of-the-art knowledge-based Word Sense Disambiguation system which uses SyntagNet to perform disambiguation in
five languages (English, French, German, Italian and Spanish) is also available from the same website (will be
demoed at ACL 2020!).
SyntagNet
is an output of the MOUSSE
ERC Consolidator Grant No. 726487
and of the ELEXIS
project No. 731015 under the European
Union’s Horizon 2020 research and innovation
programme. Babelscape
proudly developed the online interface and API, and provides the infrastructure for maintaining the service.
The
Sapienza NLP group

KONVENS 2016
http://www.linguistics.rub.de/konvens16/
The Conference on Natural Language Processing (“Konferenz zur Verarbeitung natürlicher Sprache”, KONVENS) aims at offering a broad perspective on current research and developments within the interdisciplinary field of natural language processing. It allows researchers from all disciplines relevant to this field of research to present their work. The conference will take place September 19–21, 2016 in Bochum (Germany). We are pleased to announce that John Nerbonne and Barbara Plank will give invited talks at the conference.
Call for Papers
We welcome original, unpublished contributions on research, development, applications and evaluation, covering all areas of natural language processing, ranging from basic questions to practical implementations of natural language resources, components and systems.
The special theme of the 13th KONVENS is: “Processing non-standard data — commonalities and differences”.
A wide range of data can be considered “non-standard” because it deviates in one way or the other from standard written data such as newspaper texts. Examples include:
* data produced by language learners
* historical data
* data from social media
* (transcriptions of) spoken data
We especially encourage the submission of contributions comparing different types of non-standard data and their properties, focussing on their impact for natural language processing. For example, a feature common to many types of non-standard data is the use of non-standard spelling. However, spelling variation in learner data as compared to historical data is due to very different reasons and, most likely, resulting in very different types of non-standard spellings.
Topics that we would like to see addressed include:
* Common properties of (many) non-standard data, e.g. non-standard spelling, data sparseness, features of orality
* Impact of the commonalities and differences of non-standard data on the methods and tools that are applied to the data, e.g. normalization vs. tool adaptation, evaluation without gold standard, etc.
Important Dates
NEW: June 7, 2016 Paper submissions due
NEW: July 18, 2016 Notification of acceptance
August 15, 2016 Camera-ready copy due
September 19–21, 2016 Conference
Formats
We welcome two types of contributions:
* Full papers for oral presentation (8 pages plus references)
* Short papers for presentation as posters (4 pages plus references)
Short papers/posters can be combined with a system demonstration. Reviews will be anonymous. Accepted full and short papers will be published in the conference proceedings.
Submissions must conform to the formatting guidelines, and must be made electronically through the conference website (see https://www.linguistics.ruhr-uni-bochum.de/konvens16/call/index.html#formatting-guidelines).
The conference languages are English and German. We encourage the submission of contributions in English.
Presentation by Phillippe Blache, Laboratoire Parole et Langage, CNRS & Aix-Marseille Université
Part of the Measuring ling. complexity: A multidisciplinary perspective workshop at UCL, Belgium, 24 April 2015
Complexity means different things to different people
System vs Structural complexity (Dahl, 2004)
Existing models: incomplete dependency hypothesis, dependency locality theory, early intermediate constituents principle, activation. However, they all fail to describe language in natural environment.
Challenges: dealing with natural data and dealing with language in its context, esp. spoken language and natural interaction.
Hypothesis: difficulty depends on the search space size. The larger the search space, the more difficulty.
The more properties, the smaller the search space. Maximize online principle (Hawkins, 2004).
Generative grammar is a very restrictive view.
Property grammars: linguistic statements as constraints (filtering + instantiating)
Basics: constraints are independent, linear precedence.
Constraint violation is possible.