This seems like an interesting Youtube channel. Florencia Henshaw
@Prof_F_Henshaw looks at relevant SLA research papers and provides an overview of their contents and implications for research in the field. So far (end of July 2021) two episodes have been published.
Category: SLA
There are infinite ways of using language
Epistemological relativity, for an ELT professional, means that one accepts
that there are infinite ways of using language and that differences do not
automatically call for judgmental evaluation. (Leung, 2005: p. 138)
Leung, C. (2005). Convivial communication: Recontextualizing communicative competence. International Journal of Applied Linguistics, 15(2), 119-144.
Check other quotations here.
An equitable CALL / SLA interface

From Ortega, L. (2017) New CALL-SLA Research Interfaces for the 21st Century: Towards Equitable Multilingualism. Calico Journal, 34.3, 285–316.
The majority of the world is multilingual, but inequitably multilingual, and much of the world is also technologized, but inequitably so. Thus, researchers in the fields of computer-assisted language learning (CALL) and second language acquisition (SLA) would profit from considering multilingualism and social justice when envisioning new CALL-SLA interfaces for the future.
I remain convinced that “in the ultimate analysis, it is not the methods or the epistemologies [or the theories] that justify the legitimacy and quality of human research, but the moral-political purposes that guide sustained research efforts” (Ortega, 2005, p. 438). The need to incorporate ethics and axiology in the study of language learning seems all the more acute in our present world, where human solidarity and respect for human diversity, including linguistic diversity, is under siege, creating serious vulnerabilities for the goal of multilingualism and the lives of many multilinguals. Echoingbut also widening Chun’s (2016) call for an ecological CALL in the post-2000s era, the overarching question that I have submitted to orient CALL–SLA research interfaces for the 21st century is: What technologies, teaching paradigms, views of language, and principal uses of computers can nurture multilingualism and digital literacies for all, not just for the privileged?

5 recent papers on language complexity and learner language
Bulté, B., & Roothooft, H. (2020). Investigating the interrelationship between rated L2 proficiency and linguistic complexity in L2 speech. System, 102246.
Abstract
This study investigates the relationship between nine quantitative measures of L2 speech complexity and subjectively rated L2 proficiency by comparing the oral productions of English L2 learners at five IELTS proficiency levels. We carry out ANOVAs with pairwise comparisons to identify differences between proficiency levels, as well as ordinal logistic regression modelling, allowing us to combine multiple complexity dimensions in a single analysis. The results show that for eight out of nine measures, targeting syntactic, lexical and morphological complexity, a significant overall effect of proficiency level was found, with measures of lexical diversity (i.e. Guiraud’s index and HD-D), overall syntactic complexity (mean length of AS-unit), phrasal elaboration (mean length of noun phrase) and morphological richness (morphological complexity index) showing the strongest association with proficiency level. Three complexity measures emerged as significant predictors in our logistic regression model, each targeting different linguistic dimensions: Guiraud’s index, the subordination ratio and the morphological complexity index.
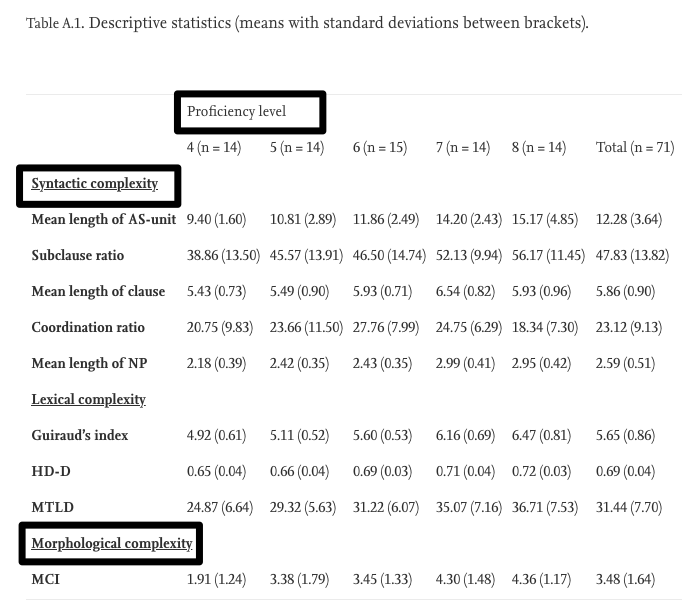
Conclusion
The present study on the relationship between nine complexity measures and five different levels of oral proficiency, as measured by the IELTS speaking test, confirms previous studies which have found that learners at higher levels of proficiency tend to produce more complex language. Even though we found higher complexity scores in higher proficiency levels for measures of lexical, syntactic and morphological complexity, the observed patterns differ substantially across measures. If we only consider differences between adjacent proficiency levels, we observed a significant increase in morphological richness (as measured by the morphological complexity index) between levels 4 and 5, in lexical diversity (Guiraud’s index) between levels 5 and 6, and in overall syntactic (mean length of AS-unit), clausal (mean length of clause) and phrasal complexity (mean length of noun phrase) as well as lexical diversity (Guiraud’s index and HD-D) between levels 6 and 7. We did not observe significant differences in complexity between the highest two proficiency levels in our dataset (i.e. 7 and 8). In addition, we found that the Guiraud index, the subclause ratio and the morphological complexity index applied to verbs were significant predictors for proficiency level in our ordinal logistic regression model, explaining around two thirds of the variance in proficiency level.
Crossley, S. (2020). Linguistic features in writing quality and development: An overview. Journal of Writing Research, 11(3).
Abstract
This paper provides an overview of how analyses of linguistic features in writing samples provide a greater understanding of predictions of both text quality and writer development and links between language features within texts. Specifically, this paper provides an overview of how
language features found in text can predict human judgements of writing proficiency and changes in writing levels in both cross-sectional and longitudinal studies. The goal is to provide a better understanding of how language features in text produced by writers may influence writing quality
and growth. The overview will focus on three main linguistic construct (lexical sophistication, syntactic complexity, and text cohesion) and their interactions with quality and growth in general. The paper will also problematize previous research in terms of context, individual differences, and reproducibility.
Conclusion
While there are a number of potential limitations to linguistic analyses of writing, advanced NLP tools and programs have begun to address linguistic complications while better data collection methods and more robust statistical and machine learning approaches can help to control for confounding variables such as first language
differences, prompt effects, and variation at the individual level. This means that we are slowly gaining a better understanding of interactions between linguistic production and text quality and writing development across multiple types of writers, tasks, prompts, and disciplines. Newer studies are beginning to also look at interaction between linguistic features in text (product measures) and writing process characteristics such as
fluency (bursts), revisions (deletions and insertions) or source use (Leijten & Van Waes, 2013; Ranalli, Feng, Sinharry, & Chukharev-Hudilainen, 2018; Sinharay, Zhang, & Deane, 2019). Future work on the computational side may address concerns related to the accuracy of NLP tools, the classification of important discourse structures such as claims and arguments, and eventually even predictions of argumentation strength, flow,
and style.
Importantly, we need not wait for the future because linguistic text analyses have immediate applications in automatic essay scoring (AES) and automatic writing evaluation (AWE), both of which are becoming more common and can have profound effects on the teaching and learning of writing skills. Current issues for both AES and AWE involve both model reliability (Attali & Burstein, 2006; Deane, Williams, Weng, &
Trapani, 2013; Perelman, 2014) and construct validity (Condon, 2013; Crusan, 2010; Deane et al., 2013; Elliot et al., 2013, Haswell, 2006; Perelman, 2012), but more principled analyses of linguistic feature, especially those that go beyond words and structures, are helping to alleviate those concern and should only improve over time. That being said, the analysis of linguistic features in writing can help us not only better understand writing quality and development but also improve the teaching and learning of writing skills and strategies.
Díez-Bedmar, M. B., & Pérez-Paredes, P. (2020). Noun phrase complexity in young Spanish EFL learners’ writing: Complementing syntactic complexity indices with corpus-driven analyses. International Journal of Corpus Linguistics, 25(1), 4-35.
Abstract
he research reported in this article examines Noun Phrase (NP) syntactic complexity in the writing of Spanish EFL secondary school learners in Grades 7, 8, 11 and 12 in the International Corpus of Crosslinguistic Interlanguage. Two methods were combined: a manual parsing of NPs and an automatic analysis of NP indices using the Tool for the Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC). Our results revealed that it is in premodifying slots that syntactic complexity in NPs develops. We argue that two measures, (i) nouns and modifiers (a syntactic complexity index) and (ii) determiner + multiple premodification + head (a NP type obtained as a result of a corpus-driven analysis), can be used as indices of syntactic complexity in young Spanish EFL learner language development. Besides offering a learner-language-driven taxonomy of NP syntactic complexity, the paper underscores the strength of using combined methods in SLA research.
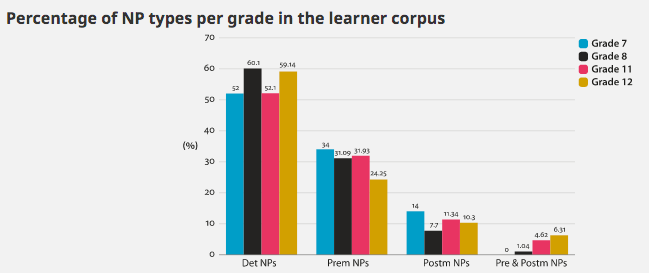
Conclusion
Our research highlights the need for using combined methods of analysis that examine the same data from different perspectives. The use of statistical complexity analysis software (Kyle, 2016) has allowed us to account for every single noun and nominal group in the corpus. The range of indices in Kyle (2016) has allowed us to approach syntactic phenomena from a purely quantitative perspective. As a result, we have found that the use of the “Nouns as modifiers” index yields significant differences between Grades 8 and 12, which confirms our finding that premodification slots are of interest for the study of learner language development. The corpus-driven manual analysis of NPs, in turn, has allowed us to gain an in-depth understanding of the types of complexity patterns used by learners in the different grades. As a result of this approach, our research has produced a learner-generated taxonomy of NP syntactic complexity that can be used in studies that examine learner language in other contexts. By combining these two research methods, we hope to make a case for their integration and to enrich methodological pluralism (McEnery & Hardie, 2012; Römer, 2016). Moreover, the findings obtained with the two methods are consistent and thus show promising avenues for collaboration and complementarity.
Two methodological features of this study are worth considering. The fine-grained classification of NP types, which includes every NP type found in the corpus, may have determined the results of the statistical analysis: the more detailed the classification of NP, the more likely it is to obtain a low number of instances in some of the NP types. Another feature to be considered is that the manual parsing conducted did not include every single noun in the corpus. This may be seen as a limitation of this study. Another limitation lies in the use of automatic analysis software and POS tagging that was not written primarily to navigate learner language. The impact of these systems on learner-language analysis has rarely been explored in corpus linguistics, and we believe that these software solutions should be sensitive to the range of disfluencies of learner language. If the small number of errors found in the use of automatic tools in learner language are considered tolerable, the automatic analysis of complexity and frequency indices in learner language can be beneficial. Finally, this study has not offered a Contrastive Interlanguage Analysis (CIA) (Granger, 1996, 2015) as it is beyond the scope of this paper to look at other L1 learners or English as an L1.
Khushik, G. A., & Huhta, A. (2019). Investigating Syntactic Complexity in EFL Learners’ Writing across Common European Framework of Reference Levels A1, A2, and B1. Applied Linguistics.
Abstract
The study investigates the linguistic basis of Common European Framework of Reference (CEFR) levels in English as a foreign language (EFL) learners’ writing. Specifically, it examines whether CEFR levels can be distinguished with reference to syntactic complexity (SC) and whether the results differ between two groups of EFL learners with different first languages (Sindhi and Finnish). This sheds light on the linguistic comparability of the CEFR levels across L1 groups. Informants were teenagers from Pakistan (N = 868) and Finland (N = 287) who wrote the same argumentative essay that was rated on a CEFR-based scale. The essays were analysed for 28 SC indices with the L2 Syntactic Complexity Analyzer and Coh-Metrix. Most indices were found to distinguish CEFR levels A1, A2, and B1 in both language groups: the clearest separators were the length of production units, subordination, and phrasal density indices. The learner groups differed most in the length measures and phrasal density when their CEFR level was controlled for. However, some indices remained the same, and the A1 level was more similar than A2 and B2 in terms of SC across the two groups.
Vercellotti, M. L. (2019). Finding variation: assessing the development of syntactic complexity in ESL Speech. International Journal of Applied Linguistics, 29(2), 233-247.
Abstract
This paper examines the development and variation of syntactic complexity in the speech of 66 L2 learners over three academic semesters in an intensive English program. This investigation tracked development using hierarchical linear modeling with three commonly‐used, recommended measures of productive complexity (i.e., length of AS‐unit, clause length, subordination) and three exploratory measures of structural complexity (i.e., syntactic variety, weighted complexity scores, frequency of nonfinite clauses) to capture different aspects of syntactic complexity. All measures showed growth over time, suggesting that learners are not forced to prioritize certain aspects of the construct at the expense of others (i.e., no trade‐off effects) across development. The unexplained significant variation found in these data differed among the measures reinforcing notions of multidimensionality of linguistic complexity.
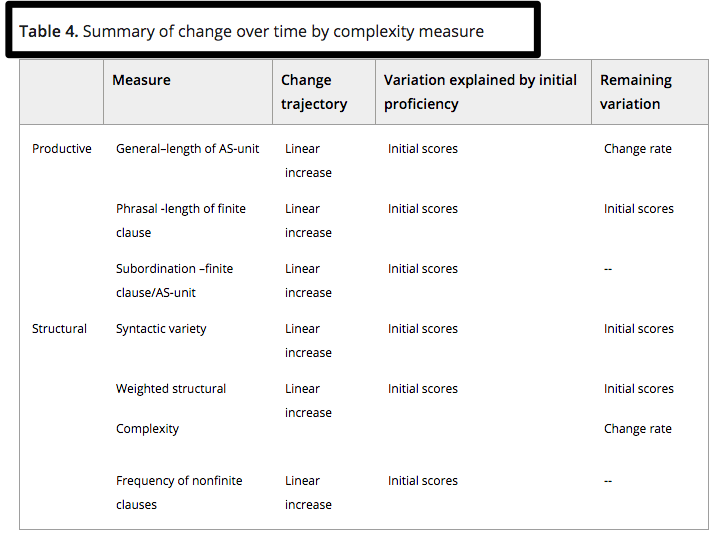
Conclusion
The results can inform the measurement choices and methodology for future English L2 research. As would be expected with language learning performance, there was substantial variation. L2 researchers likely want to use practical measures that capture the variation between individuals and across development. The variation in different parts of the measure’s models suggest that the measures capture separate aspects of complexity, and some suggestions can be offered. Subordination may serve as a practical, broad measure of complexity in instructed contexts. The easily calculated phrasal complexity revealed variation early in development, as did the weighted structural complexity measure. Moreover, researchers may want to consider using the weighted complexity measure for research investigating individual differences in language performance. One possibility is to create a measure based on standard deviation (e.g., De Clercq & Housen, 2017) of the weighted complexity measure, if the study’s purpose is to measure the variety of structural complexity in the language sample, rather than the growth of the developmentally‐aligned structural complexity. When investigating differences in language learning outcomes, general complexity and the weighted structural complexity may be useful, given the additional variation found in the models. The unexplained significant remaining variation between individuals is fodder for future longitudinal research. For instance, future research might consider how production may be influenced by the frequency and function of constructions in learners’ L1s, motivation (Verspoor & Behrens, 2011), or individual speaking style (Pallotti, 2009). Overall, this paper offers a unique comparison of syntactic complexity, both productive and structural complexity measures, advancing our understanding of this most complex construct of language performance.
Dovchin (2020): Linguistic racism and international students
Sender Dovchin (2020) The psychological damages of linguistic racism and international students in Australia, International Journal of Bilingual Education and Bilingualism, DOI: 10.1080/13670050.2020.1759504
Some extracts from this paper
The concept of ‘linguistic racism’ in this study refers to the violation of one’ s fundamental human rights based on how one speaks certain languages and how one’s entitlements are denied and discriminated against in both institutional and non-institutional settings due to how one speaks English and other additional languages (Dovchin 2019a, 2019b).
Following relevant concepts such as ‘linguicism’ (Skutnabb-Kangas 2015, 2016), ‘raciolinguistics’ (Alim, Rickford, and Ball 2016), and ‘raciolinguistic ideologies’ (Flores and Rosa 2015), the concept of ‘linguistic racism’ focuses on the central role that language plays in the enduring relevance of race/racism, institutional/ interpersonal discrimination in the lives of people of colour, ethnic minorities, international students and Indigenous people, who experience linguistic disparity as an everyday lived reality.
The main ethos of the concept of ‘linguistic racism’ seeks to understand what it means to speak as a racialized subject in the dominant societies, following Skutnabb-Kangas’s idea of ‘linguicism’ (2016, 583); ‘the ideologies, structures, and practices that are used to legitimate, effectuate, and reproduce an unequal division of power and resources between groups defined on the basis of language.’
The essential point is, thus, to recognize, following Rosa (2016, 163), racialized ideologies of certain language practices that may define what is (il)legitimate language in terms of racial and ethnic groups whose linguistic practices are stereotypically understood to correspond to standardized written text. What might appear as perceptions of ‘particular non-standardized language practices’ may, in fact, ‘racialize populations by framing them as incapable of producing any legitimate language’ (Rosa 2016, 163).
The concept of ‘linguistic racism’ is further developed in this study by adding two new dimensions – (1) ‘ethnic accent bullying’; (2) ‘linguistic stereotyping.’ First, ‘ethnic accent bullying’ refers to bullying towards English as second/foreign language speakers based on their biographical English accent – the accent connected with one’s sociolinguistic histories and biographies (Blommaert 2009; Dovchin 2019b). ‘Ethnic accent bullying’ is a form of ‘ethnic bullying’ (McKenney et al. 2006) – direct and indirect forms of bullying such as ‘racial taunts and slurs, derogatory references to culturally – specific customs, foods, and costumes,’ (McKenney et al. 2006, 242), mockery or making of fun of one’s heritage languages or accents (Scherr and Larson 2009, 226), as well as indirect or passive forms of aggression, such as ‘exclusion from a mainstream group of peers.’ (McKenney et al. 2006, 242).
‘Ethnic accent’ may also be referred to as, according to Creese and Kambere (2003, 566), ‘extra-local accent,’ ‘foreign’ or ‘immigrant’s accent,’ which signify more than hegemonic local English accents (‘Canadian,’ ‘American,’ ‘British,’ ‘Australian’ etc.), mainly embodied by racialized subjects. An ‘ethnic accent’ may shape perceptions of one’s English competency, which does not seem to elicit the same treatment as British, Australian, American, Canadian (and so on) English accents. Standard English accents and dialects, according to De Klerk and Bosch (1995, 18), often ‘connote high Status and competence’ and native speakers of English are often ‘warmly regarded, and people are predisposed to think highly of them.’ As Munro, Derwing, and Sato (2006, 71) note, ‘individuals with a foreign accent may be perceived negatively because of the stereotypes or prejudices that accent can evoke in a listener.’ Studies have hinted that the native speakers of English tend to judge ethnic accents as less prestigious than native accents (Munro, Derwing, and Sato 2006). ‘Ethnic accent,’ thus, may postulate disentitlement and inequality of its speakers in full participation in civil society (Creese and Kambere 2003, 566). The speaker with an ‘ethnic accent’ becomes what he or she speaks, and speaking it transforms him or her into what is suggested by their accent. In particular, Asian accents such as Indian, Chinese, Korean, Japanese (and so forth) accents seem to be inherently located in the hazard zone of global English accents (Blommaert 2009), often exposed to linguistic shaming such as ‘peripheral speakers as incomprehensible or as ridiculous impostors’ (Piller 2016, 197), and bullied in the popular discourse of mockery and travesty aggravated by the prejudice of people towards non-native speakers of English (Hanish and Guerra 2000). Consequently, many English speakers with immigrant backgrounds invest a lot of effort into ‘purifying’ their ethnic English accent, as Blommaert (2009, 253) notes, ‘[…] at the core of this process of purification, we see an image of the regimented, subject, someone who can face the challenges of postmodern, globalized existence provided he/she submits to the process of purification and, consequently, sacrifices his/her individual agency in a quest for uniformity and homogeneity.’ (cf. Dovchin 2017).
Second, the conception of ‘linguistic stereotyping’ expands on Piller’s (2016, 53) argument on stereotypes of English as second/foreign-language speakers, ‘[…] people who are not expected to speak a particular language (well) may be heard not to speak that language (well) irrespective of their actual proficiency.’ Language is never judged in separation from the speakers, as they face pre-fixed assumptions about his/her English fluency because of how they racially and ethnically look. The members of particular linguistic communities can be stereotyped about their voice, accent, intonation, paralinguistic signs, phonology, pronunciation, and lexicon, accompanied by evaluative connotations (De Klerk and Bosch 1995). These judgments and preconceptions have ‘a profound influence on our subconscious attitudes to languages and to Speakers of these languages’, and ‘they represent the dark side of the human abstraction process; they are often inaccurate because they simplify what otherwise might have overwhelmingly diverse meaning and indirectly influence the perception and categorization of people.’ (De Klerk and Bosch 1995, 18). In particular, Asians are often stereotyped as having low proficiency in English (Blommaert 2009). Piller (2016, 53), for example, reminds us of a now-classic experiment conducted in the 1980s at a university in Florida, where researchers audio-recorded a lecture consisting of a native speaker of American English with a standard American-English accent. The lecture was later played to two different groups of undergraduate students, complemented by the picture of a Caucasian woman in one case and the picture of an Asian woman in the other. The students who viewed the Asian lecturer reported that they heard a ‘foreign,’ ‘non-native,’ ‘Asian’ accent, reduced comprehension, and low-level quality learning experience despite the absence of that auditory signal (Piller 2016, 53).
Meanwhile, international students, who become the victims of these two types of linguistic racism – ‘ethnic accent bullying’ and ‘linguistic stereotyping,’ are often deprived of living a meaningful full social life. Because these two types of linguistic racism appear to instil a perpetual sense of ‘inferiority complexes’ (Kenchappanavar 2012, 1) such as self-marginalization, self-vindication, loss of social belonging, social withdrawal – the psychological damages resulting from the homogeny of hegemonic English (Piller 2016). Learning and speaking English means ‘to become alive to one’s marginality in English and to a perpetual falling short of the imagined ideal of “perfect” homogeneous English.’ (Piller 2016, 203). Being an ideal English speaker also means purifying and refining their accents and linguistic repertoires, while feeling the inferiority complex that their English is ‘terrible,’ ‘nonstandard’ and ‘unaccepted’ (Dovchin 2019b). An inferiority complex is a kind of psychological obstacle that arises when ‘a person finds himself in a situation where his abilities and attitudes are denigrated or rejected by other people.’ (Kenchappanavar 2012, 1). Anything in the individual that is ‘below the average, that provokes unfavourable comment or gives him a feeling of impotency or ineptitude leads to inferiority complex.’
Usage based in a nutshell (Ellis 2012)

Usage-based theories of language hold that learners acquire constructions in a similar fashion—from the statistical abstraction of patterns of form-meaning correspondence in their usage experience—and that the acquisition of linguistic constructions can be understood in terms of the cognitive science of concept formation following the general associative principles of the induction of categories from experience of the features of their exemplars. In natural language, the Zipfian-type token-frequency distributions of the occupants of each of these construction islands, their prototypicality and generality of function in these use, roles and the reliability of mappings between these together conspire to make language learnable. Phrasal teddy bears, formulaic phrases with routine functional purposes, play a large part in this experience, and the analysis of their
components gives rise to abstract linguistic structure and creativity.
Is the notion of language acquisition being seeded by formulaic phrases and yet learner language being formula-light having your cake and eating it too?
Ellis, N. (2012). Formulaic Language and Second Language Acquisition: Zipf and the Phrasal Teddy Bear. 32, 17-44.