AELINCO 2015 Conference, U. Valladolid, Spain

Andre Hardie Keynote
What follows is my own notes and understanding of Hardie’s keynote.
How big is big data?
N= ALL?
Non manual curation of the database
Must be mined or statistically summarised (manual not posssible)
Pattern finding: trend modelling, data mining & machine learning
Language big data: Google n-gram
A revolutionary change for language and linguistics?
Textual big data studies sone by non-linguistic specialists
Limitations of Google when used with no language training
Michel et al. Quantitative analysis if Culture. Science 331 (2011). Culturomics. What is there?
Quantitative findings, otherwise pretty predictable and very much frequency counts. In actual fact, the study was not backed by any expert in corpus linguistics. Steven Pinker was involved in the paper and the whole thing was treated as if they invented the wheel.
Borin et al. papers trying to “salvage” the whole cultoromics movement from its ignorance.
New “happiness” analyses are trendy, but what do they have to offer? Lots of problems attached and shortcomings. I think that corpus analysis is becoming mainstream and it is more visible in specialized journal. The price of fame?
Linguistically risibly naive research done by non-linguists

Paul Rayson keynote
Larger corpora available from Brown in the 1960’s
Mura Nava’s resource. An interesting timeline of corpus analysis tools.
SAMUELS : Semantic Annotation and mark-up for enhancing lexical searches
Overcoming problems when doing textual analysis: fused forms, archaic forms, apostrophe, and many many others…. Searching for words is a challenge > frequencies split by multiple spellings.
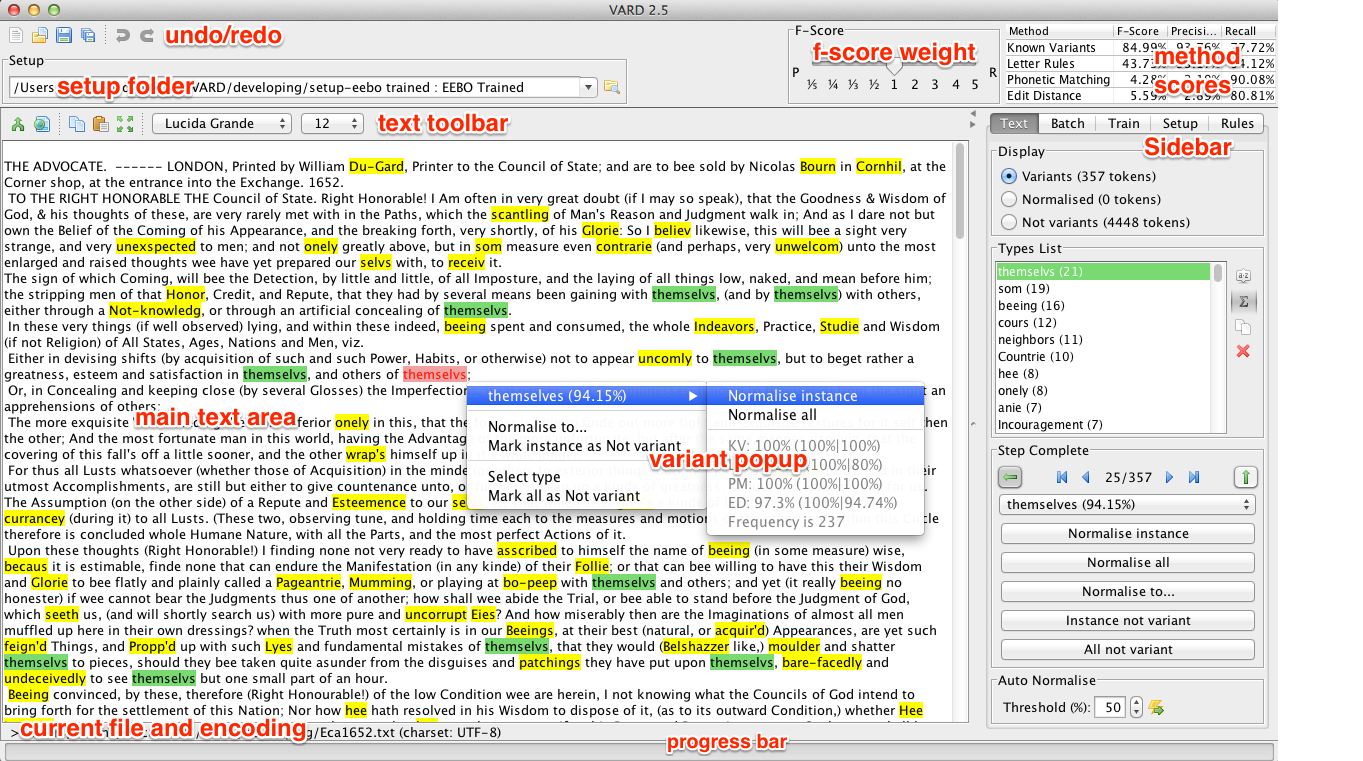
VARD
USAS semantic tagger
Full text tagging (as opposed to trends in “textual big data” analysis).
Modern & historical taggers
Disambiguation methods are essential
Paul discusses the Historical Thesaurus of English
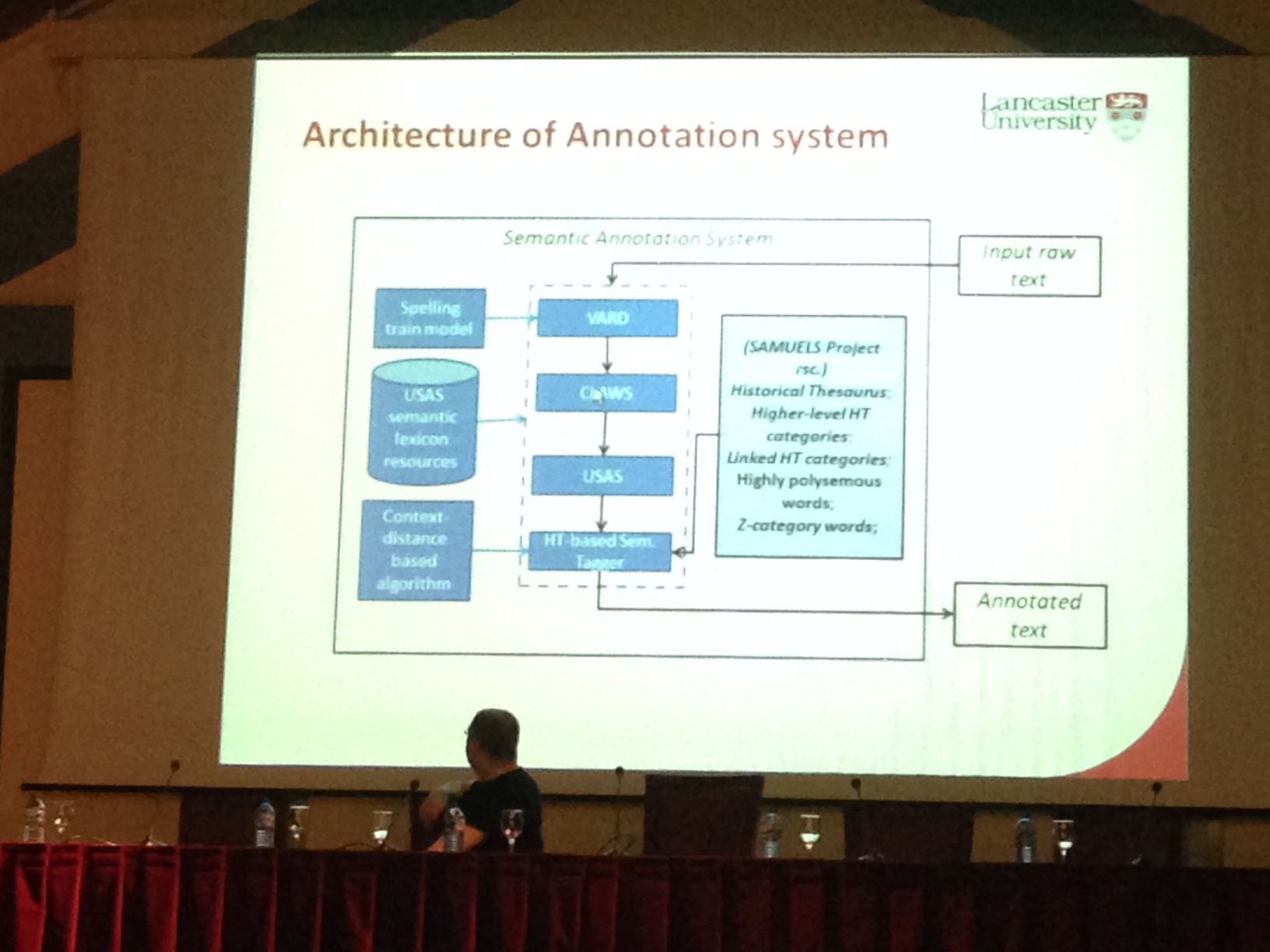
The whole annotation system:
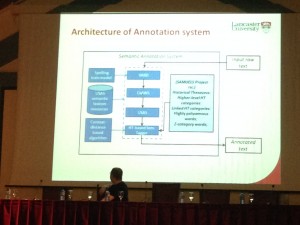
I guess this is the missing part in big data as practised by non-linguists.