
SLA Research Colloquium
Venue: Drama Studio, UCL Institute of Education, University College London, 20 Bedford
Way, London WC1H 0AL
Date: Saturday, 14th May 2015 (10 am – 4.15 pm)
10:00 – 10:10
Welcome, introduction and opening remarks

10.10 – 10.45
Kazuya Saito (Birkbeck College)
Role of individual differences in second language speech learning: A longitudinal study

10.45 – 11.20
Pauline Foster (St. Mary’s University)
From ideal to idiolect: the trajectories of nativeness within and without SLA research.
Newbolt Report 1921: only Standard is a full language, the rest is full of lower-class vulgarismo. School is crucial for SE to root.
Bernstein 1958: Some sociological determinants of perception. Low class language as a restricited code, not elaborated. Working class deficits.
There are as many native languages as native speakers, rejection of monolithic views. No fixed target to aim for, no model to study no baseline. Scholz (2002) rejects this idea. Morgan (1986) mastery of prestige rules is exploited socially to signa, membership to a higher class.
Weiss (2004) says two kinds of NS. One is subject to FLA , the other to education.

11:40 – 12.15
Luke Plonsky (UCL Institute of Education) & Deirdre Derrick (Northern Arizona University)
Alpha, kappa, KR-20, oh my! A synthesis and guide to interpreting reliability estimates in L2 research
To appear in Modern Language Journal (2016)
Reliability: consistency and repeatability in assessment/ data collection.
An indication of the amount of error in the data.
Expressed as coefficient from 0 to 1 (alpha, kappa)
Internal consistency: instrument reliability: how similar are the items seeking to measure the same thing
Interrater consistency
Reliabilty rarely reported
Often low: Cohen & Macaro (2013). Error in our data. Attenuation (reduction) of observed effects/ relationships.
Low is unclear
Shrout 1998 in psychiatry slight .11-.40 fair .41-.60
Should not be applied blindly . Reliability as a continuum. There are lots of different variables that may impact reliability: samples (size, proficiency,), instruments and the indices used.
Kappa is used for categorical data (raters for example categorizing a writing sample A B C)
Reliability generalization meta-analysis, an example is Watanabe & Koyama (2008).
RQ What is the overall observed reliability in 2009-2013 SLA research?
537 studies = 2,244 reliability coefficients
Aggregated all and obtained the median (and IQR) for 3 types of reliability
-Instrument: 0.82 k=1323
-Interrater: 0.92
-Intrarater: 0.95

Reliability is getting reported more over time
Focus on instrument:
As levels of informants increase, more instrument reliability: for beginner 0.79
Linguistic constructs: 0.81 and mon linguistic: 0.83
Receptive skills, less reliability scores
Multiple choice 0.81
Free response 0.85
The more items in the scale the more reliable
Different indices:
KR 20
KR21
ALPHA
Split-halves
Spearman-Brown
Plonsky(2013)
12.15 – 12:50

Paul Booth (Kingston University)
Semantic and syntactic predictions: investigating the extent to which L1 learner choices influence the L2
Models of lexical development: Levelt (1989) & Jiang (2000)
Levelt: semantics + syntax more difficult to acquire than morphology and phonology
Jiang: L1 semnatics and syntax influence how l2 items are acquired
Groups of Japanese and Europeans and English NS
X-Lex (v2.05) and Y-lex (v2.05): vocabulary measures
Vocabulary a good predictor of language proficiency
DMDX: response times and accuracy are interpreted to draw inferences about cognitive processing
They are looking at reaction times
All groups did better on the noun-noun (correct/incorrect) than the mixed set
All groups more accurate responses for noun groupings compared to mixed set
There is a effect for grammatical category, so more difficult for all groups.
Overall effect for first language groups (Japanese slower to reject ungrammatical syntax)

14.00 – 14.35
Parvaneh Tavakoli (University of Reading)
Development of second language proficiency in monologic vs dialogic mode: Can CAF measures portray the full picture?
Performance can usefully be measured by CALF (Skehan, 1996-2015)

Benefits in using CALD measures:
Tap into different aspects of language ability
Help shed light on processes underlying SLA (attention, allocation, noticing, memory), representation , etc
Palloti (2009, 2015): accuracy and complexity may not indicate interlanguage development
Product (performance) vs process (development)
Measures sensitive to language development are needed
Communicative adequacy (Kuiken, Veder & Gilabert, 2010; Palloti, 2009
WISP project, de Jong et al. 2012
CALC project, Kuiken en tal, 2010
Revesz et al. 2014: fluency is a good predictor of proficiency
Limitations in this area:tendency to use monologic task performance BUT importance of dialogic task performance
PRAAT
Monologic vs dialogic task performance, Time 1 and 2

Development of lexis needed more research
What else can be measured? Task accomoishment, fulfilling language function, development in intereactions
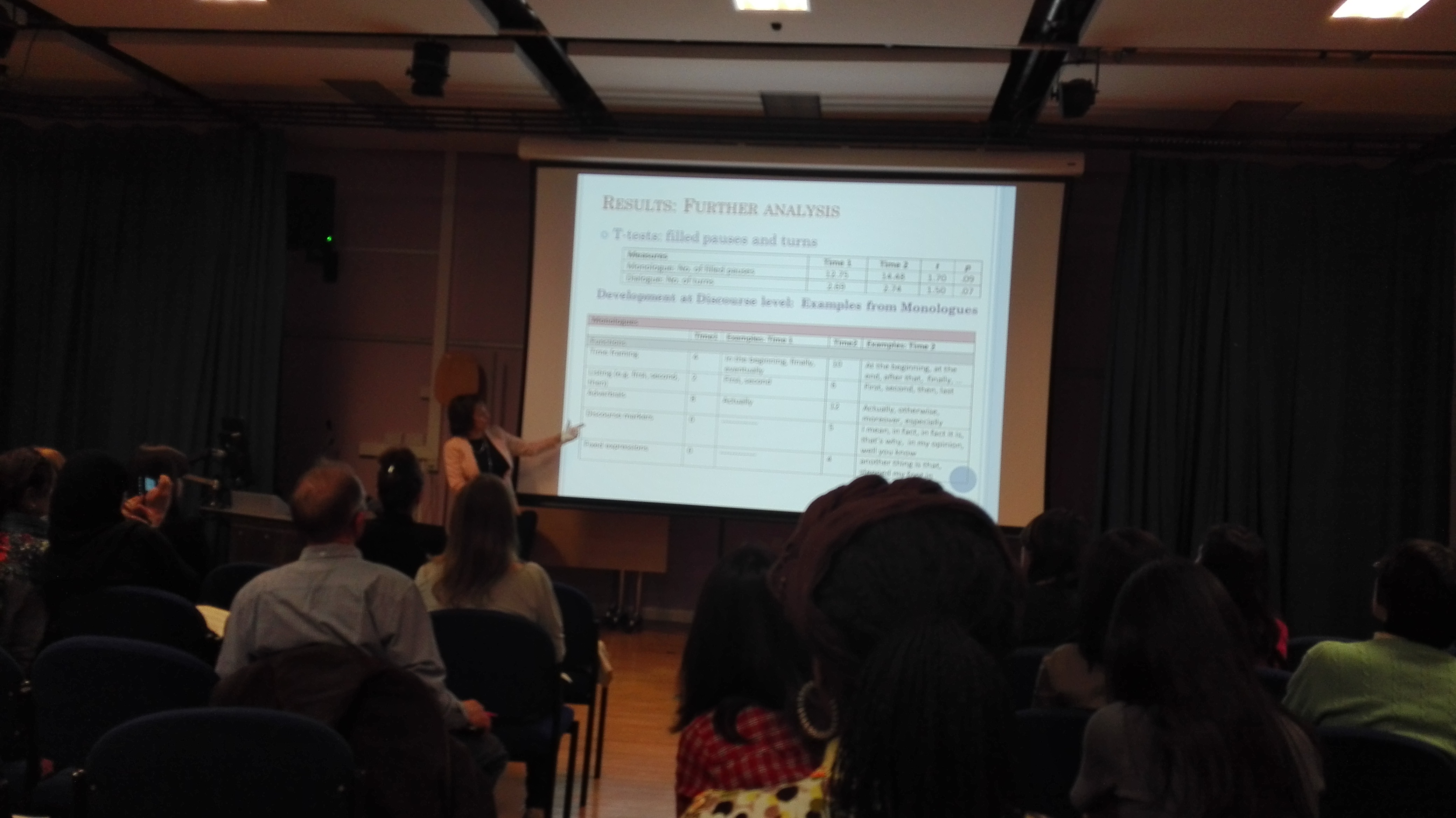
Much of the development at discourse level she looked at adverbials, particularly adverbs

14.35 – 15.10
Peter Skehan (St. Mary’s University) & Zhan Wang (The University of Hong Kong)
The effects of time pressure and L2 proficiency level on task-based speaking performance
15.10 – 15.45
Andrea Révész (UCL Institute of Education), Marije Michel (Lancaster University), & Diana Mazgutova (Lancaster University)
The effects of proficiency on second language writing behaviours and text quality
15.45 – 16.15
Final discussion and closing remarks